Crush AI Agent Memory Limits to Boost Context by 40%
Key Takeaways:
- Amnesia is an Architecture Problem: Your AI agent isn't stupid; it just has amnesia because your context window strategy is flawed.
- Beyond the Prompt: Relying solely on a model's native context window limits scalability and drastically inflates token costs.
- Vector Databases are Mandatory: You must architect long-term memory solutions so your agents actually remember past workflow states.
- Infrastructure First: 50% of agentic AI pilots fail due to infrastructure, not UX. Memory is a core infrastructure requirement.
- Sprint for State Management: Product teams must dedicate entire sprint cycles to building Retrieval-Augmented Generation (RAG) pipelines for their autonomous workers.
If your autonomous workflows keep forgetting instructions halfway through a task, you are hitting AI agent memory limits. This is the silent killer of enterprise automation.
The most sophisticated prompt engineering in the world cannot save a system that mathematically drops context after a few thousand tokens. While managing synthetic team members is crucial, the ultimate differentiator for a 2026 Product Leader is mastering the underlying orchestration and memory infrastructure required to scale them.
You can no longer treat artificial intelligence as a simple conversational interface; it requires rigorous state management. Welcome to the demanding reality of Agentic Product Management.
To build reliable AI that retains context across complex, multi-day tasks, you must fundamentally restructure how you approach Sprint Planning. This deep dive will show you exactly how to crush memory bottlenecks and build resilient, stateful agents.
The Reality of AI Agent Memory Limits
Large Language Models (LLMs) are inherently stateless. Every time an API call is made, the model processes the prompt as if it is interacting with the user for the very first time.
To create the illusion of a continuous conversation, product teams typically append the entire chat history to every new prompt. This brute-force approach works for simple chatbots but collapses under the weight of enterprise agentic workflows.
Why the Brute-Force Method Fails:
- Token Exhaustion: You quickly hit the hard cap of the model's context window.
- Cost Explosions: Sending massive, repetitive context payloads continuously drains your API budget.
- Attention Degradation: Even models with massive context windows suffer from "lost in the middle" syndrome, ignoring crucial instructions buried in massive text blocks.
To survive, you must architect long-term memory solutions so your agents actually remember past workflow states.
Short-Term Context vs. Long-Term Memory
Before grooming your backlog, you must understand the technical distinction between how an agent processes immediate tasks versus how it retains historical data.
Short-Term Context (The Working Memory)
This is the agent's immediate scratchpad. It consists of the specific prompt, the current system instructions, and the immediate variables required to execute a single action.
- Sprint Goal: Optimize prompt templates to be as concise as possible.
- Limitation: Highly volatile. Once the API call resolves, this memory is essentially wiped unless manually preserved.
Long-Term Agent Memory (The Storage Drive)
This is where true autonomous capability lives. Long-term memory allows an agent to recall a decision it made three weeks ago or reference a 500-page compliance document without keeping it in the active prompt window.
- Sprint Goal: Implement vector database AI integration.
- Limitation: Requires complex retrieval architectures and constant database maintenance.
Sprint Planning for Memory Architecture
How do you translate these complex infrastructural needs into an Agile framework? You cannot simply write a Jira ticket that says, "Make the agent remember things."
You must break the architecture down into actionable, testable user stories. This often involves tackling severe agentic AI pilot-to-production bottlenecks when setting up the underlying hosting environments for your databases.
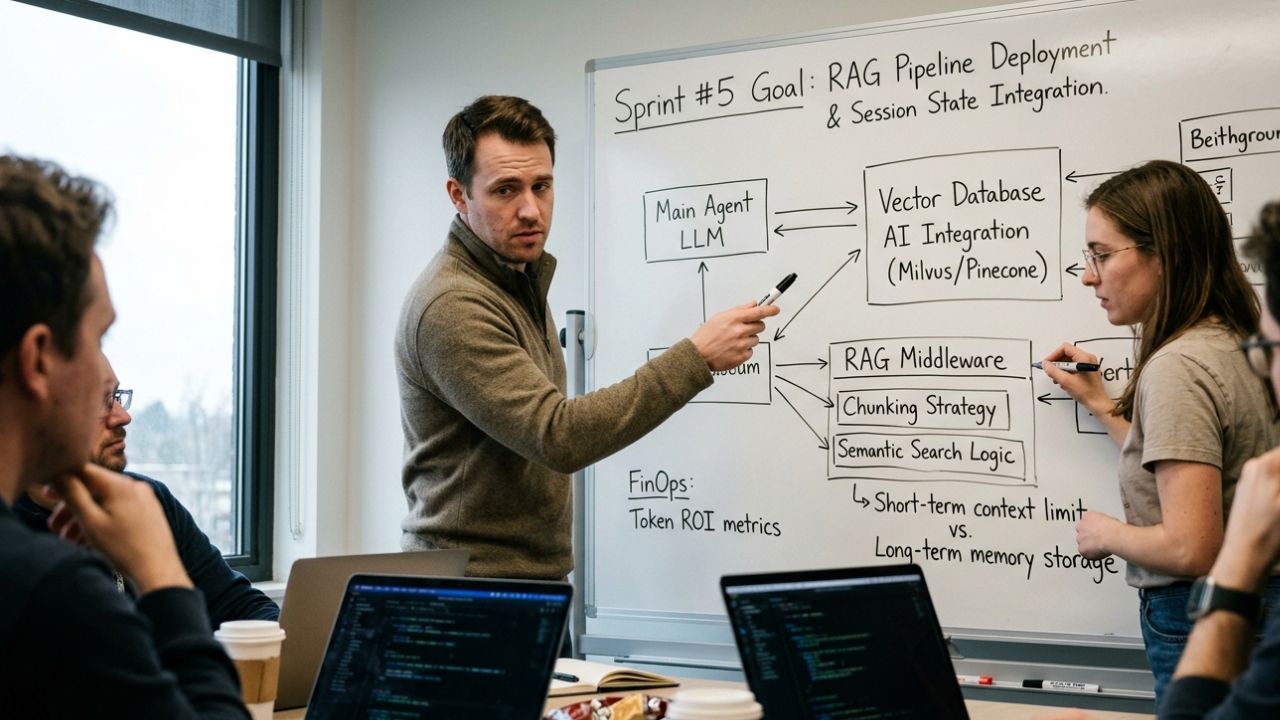
Sprints Dedicated to Vector Database Integration
Your first architectural sprint should focus exclusively on deploying and connecting a vector database (such as Pinecone, Weaviate, or Milvus).
- Database Provisioning: Set up the cloud infrastructure to host the vector embeddings securely.
- Embedding Pipelines: Build the microservice that converts enterprise data (PDFs, past agent logs) into mathematical vectors.
- API Connectivity: Establish secure, low-latency connections between your orchestration layer and the vector database.
Defining RAG Workflows in Your Backlog
Retrieval-Augmented Generation (RAG) is the specific mechanism by which your agent queries the vector database before taking action.
- Semantic Search Logic: Ensure the agent can query the database based on the meaning of a task, not just exact keyword matches.
- Context Injection: Write the middleware that takes the retrieved database information and seamlessly injects it into the agent's immediate prompt window.
- Chunking Strategies: Define how large documents are broken down before being embedded to optimize retrieval accuracy.
Advanced State Management for Autonomous Agents
Overcoming AI agent memory limits isn't just about reading old data; it's about continuously writing new data as the agent works.
If a multi-agent system is processing payroll, it must record every micro-decision it makes. This is called session state management, and it is a critical deliverable for your engineering sprints.
Building the State Tracker
During sprint execution, developers must build a state-tracking database (often a high-speed key-value store like Redis).
- Event Logging: Every time an agent completes a sub-task, it updates its status in the state tracker.
- Resilience: If the agent crashes or the API times out, the system reads the state tracker to resume exactly where it left off.
- Cross-Agent Visibility: Other agents in the swarm can query the state tracker to understand what their peers are currently doing.
Security and Data Purging
Memory is a massive security liability. If your agent is reading and writing sensitive enterprise data, your sprints must include robust data governance stories.
- Time-to-Live (TTL): Implement strict TTL policies on your vector embeddings. Data should automatically delete after a specified period.
- Secure Wiping: Create user stories for "forgetting" data. If a user requests data deletion under GDPR, your agent's memory banks must be purged immediately.
- Role-Based Memory Access: Ensure an agent handling marketing tasks cannot query the vector namespace dedicated to HR payroll data.
Measuring Sprint Velocity with AI Memory
Integrating memory architectures fundamentally changes how you measure sprint velocity. Traditional story points do not account for the latency introduced by vector searches.
FinOps and Performance Metrics to Track:
- Retrieval Latency: How many milliseconds does it take the agent to query the vector database and inject the context?
- Token Efficiency: Are you successfully reducing the raw token count in your main prompts by relying on targeted RAG injection?
- Hallucination Reduction: Measure the decrease in fabricated outputs once the agent has reliable historical state access.
By tracking these specific metrics, Product Managers can prove the tangible ROI of their infrastructure sprints to executive stakeholders.
Conclusion
Scaling autonomous systems requires a fundamental shift in how you build software. You cannot achieve true enterprise automation if your synthetic workers suffer from chronic amnesia.
To successfully bypass AI agent memory limits, you must stop treating AI as a stateless conversational tool. Dedicate your sprint planning to deploying robust vector databases, optimizing Retrieval-Augmented Generation (RAG) pipelines, and enforcing strict session state management.
By focusing on the underlying infrastructure rather than just prompt engineering, you ensure your agents retain context, reduce API costs, and execute complex workflows with deterministic precision.

Frequently Asked Questions (FAQ)
Q1: What causes AI agent memory limits?
A: AI agent memory limits are caused by the hard constraints of an LLM's context window. Models process text in tokens, and once a prompt exceeds this finite token budget, the model drops older information, resulting in complete context loss and workflow amnesia.
Q2: How do you give an AI agent long-term memory?
A: You give an AI agent long-term memory by integrating a vector database. Instead of relying on the active prompt window, the agent converts past interactions and enterprise data into embeddings, querying this database via Retrieval-Augmented Generation (RAG) when historical context is needed.
Q3: What is the difference between short-term context and long-term agent memory?
A: Short-term context refers to the immediate information stored in the LLM's active prompt window, which is highly volatile and limited by token caps. Long-term memory utilizes external vector databases to store and retrieve historical workflow states indefinitely, bypassing token limitations completely.
Q4: How do vector databases solve LLM context window limits?
A: Vector databases solve LLM context window limits by storing massive amounts of data as mathematical embeddings outside the model. When an agent faces a task, it uses semantic search to retrieve only the highly relevant data chunks, injecting them into the immediate prompt.
Q5: Why do AI agents forget instructions during complex workflows?
A: AI agents forget instructions during complex workflows because their context windows become bloated. As a continuous loop runs, the conversational history pushes the original system instructions out of the model's active processing capacity, leading to severe hallucination and failure to execute core tasks.