The Multi-Agent Orchestration Workflows Big Tech Hides
Key Takeaways:
- Ditch the Monolith: Relying on a single, massive AI model to do everything is the fastest way to bloat your cloud bill and degrade performance.
- Sprint on Infrastructure: 50% of agentic AI pilots fail due to infrastructure, not UX. Sprints must focus on the routing layer.
- Specialized Swarms Win: The future belongs to specialized, highly orchestrated multi-agent swarms—here is how to build the routing layer.
- Control the Handoff: Fragmented agents kill ROI. Unifying them requires strict, predictable handoff protocols and API contracts.
- Focus on Architecture: The ultimate differentiator for a 2026 Product Leader is mastering the underlying orchestration and memory infrastructure required to scale them.
Scaling enterprise AI is no longer about writing better prompts; it is a brutal infrastructure challenge. While managing synthetic team members is crucial, building the systems that allow them to communicate is even more critical.
If you are hitting scaling bottlenecks, you must master the multi-agent orchestration workflows used by top CTOs to unify autonomous tasks. The foundation of this scaling strategy relies on advanced Agentic Product Management.
Without a structured approach to workflow orchestration, autonomous systems quickly descend into chaos, consuming massive compute resources while delivering non-deterministic, unusable results. This deep dive exposes the secret multi-agent orchestration workflows that Big Tech hides.
We will break down exactly how to structure your sprint planning to architect these complex routing layers, ensuring your next enterprise deployment avoids pilot purgatory and scales efficiently.
Why Traditional Sprints Fail for Agentic Workflows
Traditional Agile methodologies assume a linear, deterministic development cycle. You write a user story, code the logic, and test the output. However, AI agents completely break this paradigm.
When product teams attempt to map complex business logic to a single AI model, they experience massive failure rates. Single models suffer from severe context window limitations, hallucination spikes, and exorbitant latency when forced to act as a "jack of all trades."
The Monolith Fallacy
According to recent insights from AI researchers at Microsoft (creators of the AutoGen framework), forcing a single LLM to execute complex, multi-step logic is highly inefficient. The resulting issues include:
- Context Bloat: The model forgets early instructions as the prompt grows.
- Latency Spikes: Massive prompts require significant compute time to process.
- Cost Overruns: Running every minor task through a frontier model destroys profit margins.
To survive, your sprint planning must shift from prompt engineering a single model to designing a system of specialized workers.
Architecting Enterprise Agentic AI at Scale
The enterprise landscape is currently facing a massive hurdle. Let's briefly examine the "2026 Capacity Crunch" and why 50% of agentic AI pilots fail due to infrastructure, not UX.
When scaling LLM agents, compute limitations and API rate limits become the primary blockers. Sprints must prioritize the infrastructure layer. Product Managers must architect workflows that divide labor intelligently among autonomous agent swarms.
Core Orchestration Architectures
During your sprint planning sessions, the engineering team must align on the specific multi-agent system architecture you intend to build.
- The Supervisor Model: A primary orchestrator agent receives the user prompt and delegates sub-tasks to specialized worker agents.
- The Hierarchical Model: Multiple layers of management agents oversee different domains, summarizing data before passing it up the chain.
- The Networked Swarm: Agents operate on an event bus, picking up tasks asynchronously as they appear in the queue, similar to microservices.
Choosing the right architecture in Sprint 0 dictates the success of your entire AI initiative.
Sprint Planning Step 1: Building the Routing Layer
The first major sprint in your AI product roadmap should completely ignore the end-user interface. Instead, you must dedicate sprints to building the routing layer.
Defining the Agent Roster
Before writing any code, Product Managers must define the exact roles of the AI task delegation. Create a strict roster for the sprint:
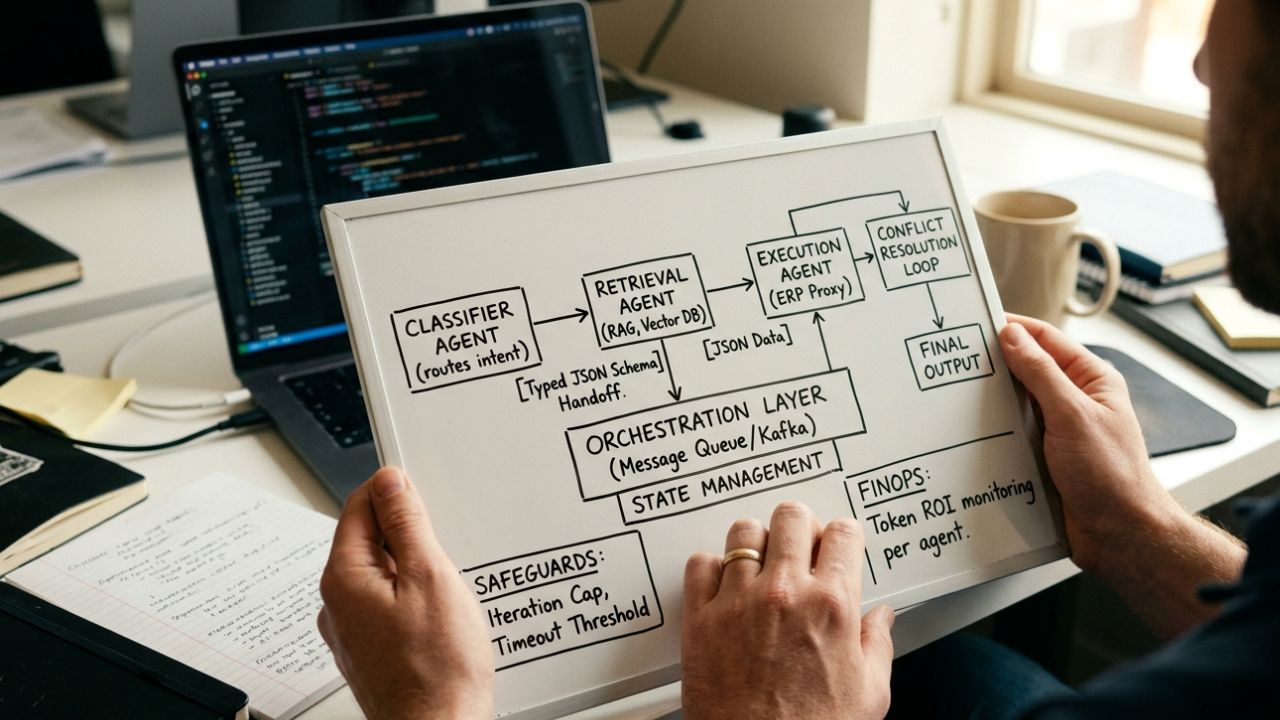
- The Classifier Agent: Only identifies user intent and routes the query.
- The Retrieval Agent: Only interacts with the vector database for RAG.
- The Execution Agent: Only interfaces with external APIs to take action.
Mapping the Handoffs
How do you design handoffs between specialized AI agents? This is the most critical user story in your sprint backlog.
Handoffs must be strictly typed. If the Classifier Agent routes data to the Retrieval Agent, it must do so using a rigid JSON schema. Your sprint goals must include writing the validation logic that rejects any improperly formatted data passed between synthetic team members.
Sprint Planning Step 2: Communication and Conflict Resolution
Once the routing layer is established, subsequent sprints must tackle inter-agent dialogue. Managing communication between multiple AI agents requires treating them like distinct microservices.
Event-Driven AI Workflows
Do not rely on synchronous API calls between agents. If Agent A waits for Agent B, your latency will skyrocket. Sprint deliverables should include:
- Implementing a message broker (like Kafka or RabbitMQ) for agent communication.
- Creating dead-letter queues for agent tasks that fail repeatedly.
- Establishing asynchronous webhooks for final task delivery.
Conflict Resolution Protocols
How do AI agents resolve conflicts in a workflow? What happens when the coding agent writes a script, but the QA agent rejects it?
Your sprint planning must account for these loops. Product managers must define the maximum number of iterations allowed. If the QA agent rejects the code three times, the workflow must automatically escalate to a human developer to prevent infinite resource drain.
Sprint Planning Step 3: Governance and Loop Prevention
The nightmare scenario for any CTO is an autonomous swarm caught in an infinite loop, silently burning through cloud credits over a weekend.
Hard Coding the Boundaries
How do you prevent infinite loops in multi-agent workflows? You cannot rely on the AI's "common sense" to stop itself. Include these safeguards in your sprint:
- Iteration Caps: Hardcode a maximum number of steps any agentic workflow frameworks can execute.
- Timeout Thresholds: If an agent takes longer than 45 seconds to reason through a problem, kill the process.
- Deterministic Circuit Breakers: Implement traditional, non-AI logic rules that override the agents if specific negative conditions are met.
Properly scoping these governance features is essential for productionizing AI workflows.
Sprint Planning Step 4: Measuring Token ROI
You cannot scale multi-agent orchestration workflows without strict financial monitoring. Efficient routing directly reduces token spend.
Integrating FinOps into Agile
Every sprint retrospective must now include an analysis of agentic AI token economics. Metrics to track per sprint:
- Average token cost per successful multi-agent workflow completion.
- The ratio of successful routing events to hallucinated handoffs.
- The compute cost of your Supervisor agent versus your specialized worker agents.
By pushing smaller, specialized tasks to cheaper, open-source models, while reserving frontier models for the main orchestration layer, teams can drastically improve their operating margins.
Expanding the Content Hub
To fully master the 2026 AI landscape, your product teams must cross-train on adjacent infrastructure requirements. Explore our deep dives on building robust synthetic teams:
- Data Security: Why integrating AI agents with legacy ERP Fails Audits
- State Management: Crush AI agent memory limits to Boost Context by 40%
- FinOps: Why Your agentic AI token economics Will Bankrupt You
- Deployment: Overcome agentic AI pilot-to-production bottlenecks and Ship 40% Faster
Each of these elements ties directly back into how you map business logic to autonomous agent swarms, ensuring your product is built for scale.

Frequently Asked Questions (FAQ)
Q1: What are multi-agent orchestration workflows?
A: Multi-agent orchestration workflows are structured frameworks that coordinate several specialized artificial intelligence models to complete complex tasks collectively. Instead of using a single monolithic model, this approach routes specific sub-tasks to dedicated autonomous agents, improving accuracy, reducing latency, and lowering overall operational costs significantly.
Q2: How do you manage communication between multiple AI agents?
A: Managing communication between multiple AI agents requires a robust routing layer and strict API contracts. Product teams must establish standardized data formats, like JSON schemas, and utilize message queues or event-driven architectures to ensure agents exchange state updates reliably without dropping context or creating bottlenecks.
Q3: What is the best architecture for multi-agent systems?
A: The best architecture for multi-agent systems typically involves a hierarchical or supervisor-based routing layer. A primary agent acts as the orchestrator, delegating distinct tasks to specialized worker agents based on their predefined capabilities, which minimizes cloud compute waste and prevents individual models from context overload.
Q4: How do you prevent infinite loops in multi-agent workflows?
A: To prevent infinite loops in multi-agent workflows, product managers must define strict execution boundaries during sprint planning. Implementing hard iteration caps, timeout thresholds, and deterministic conflict resolution protocols ensures that autonomous agents will automatically halt and request human intervention rather than endlessly passing data back and forth.
Q5: What is the role of a Product Manager in multi-agent design?
A: The role of a Product Manager in multi-agent design is to map complex business logic directly to autonomous agent swarms. They must prioritize building the routing infrastructure, define strict handoff protocols, and closely monitor token economics to ensure the orchestrated system delivers measurable, cost-effective business value.