« Back to Pillar Page: The AI Product Manager Guide
How to Build a Synthetic User Focus Group Using AI

- Updated prompt engineering tactics to align with the expanded 1-million+ token context windows of Gemini 3.1 Pro and Claude 4.7.
- Added crucial compliance guidelines for synthetic data under the EU AI Act's Article 50 transparency requirements.
- Introduced multi-turn interview strategies to prevent hallucination drift in long-running simulations.
Executive Summary (TL;DR)
- Speed over perfection: Synthetic user testing is not a replacement for human empathy; it is a rapid preliminary filter. It allows you to simulate thousands of product interactions before writing a single line of code.
- Context is everything: Asking a raw LLM to "act like a customer" produces generic garbage. True synthetic personas require deep context grounding via Retrieval-Augmented Generation (RAG) using your actual CRM and support data.
- Cost efficiency: By transitioning to agentic AI product management, product teams drastically reduce the $100/hr incentive costs typically associated with early-stage discovery.
- Compliance matters: You must strip Personally Identifiable Information (PII) before vectorizing historical transcripts to avoid severe GDPR and EU AI Act penalties.
Introduction: The "Always-On" Focus Group
Imagine if you could wake up your target audience at 3 AM to test a new value proposition, get instant feedback, and pay absolutely zero in user incentives. In 2026, this is no longer a futuristic fantasy—it is the baseline for product discovery automation.
Synthetic users for product research are not generic chatbots reciting Wikipedia. They are highly specific, stateful AI personas modeled strictly on your company's actual customer data. By simulating user feedback with massive LLMs, Product Managers can test hypotheses in minutes rather than waiting weeks for UX researchers to recruit participants. This approach drastically reduces user research costs and tightens the feedback loop.
By utilizing advanced product discovery with AI, teams can discard fundamentally flawed ideas before they reach the engineering backlog. This guide breaks down the mechanics of generative AI for market research and provides the exact framework to build your own AI focus groups.
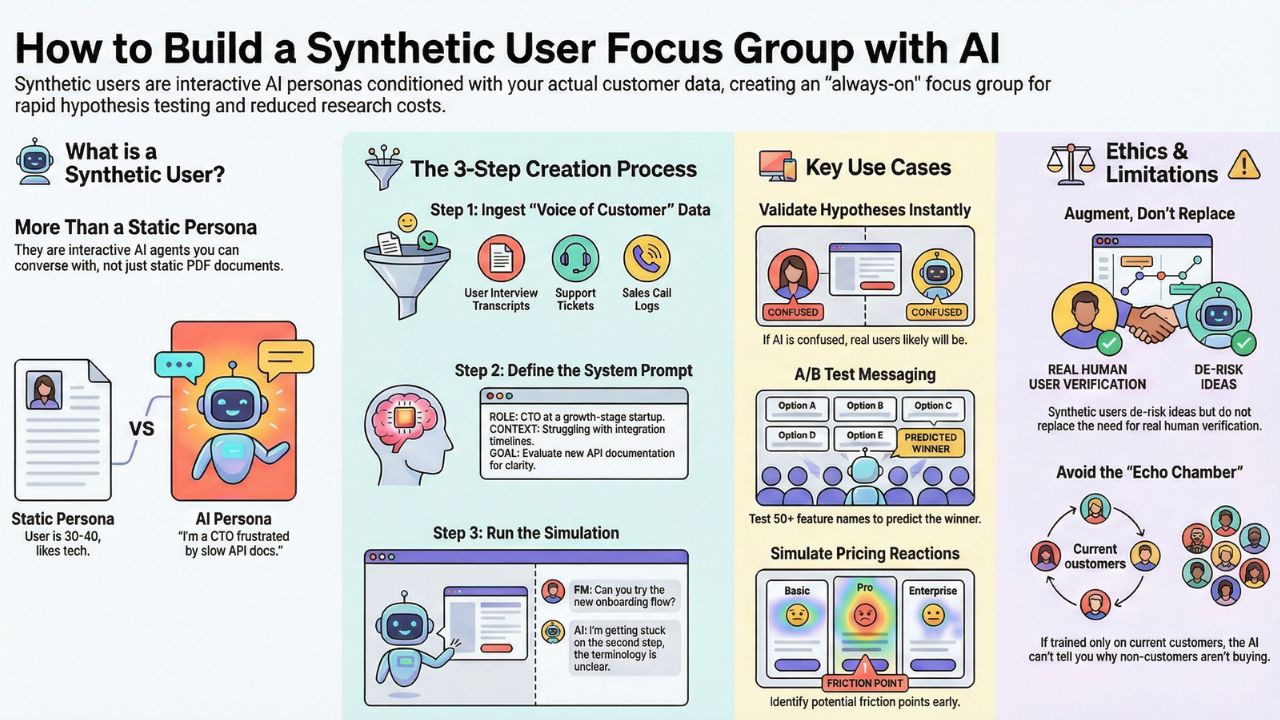
1. What Are Synthetic Users? (Beyond Demographics)
A "Synthetic User" is a large language model that has been algorithmically conditioned with precise psychographic data, behavioral traits, and historical friction points. Unlike traditional personas—which often rot in a static PDF on a shared drive—synthetic users are interactive and dynamic. You converse with them, and they react to your prototypes.
- The Static Persona: "User is a 30-40 year old professional who likes technology and needs efficiency."
- The AI Persona: "I am Sarah, a 34-year-old Director of Engineering. I am currently frustrated by the slow indexing speed of our internal API documentation. I previously churned from a competitor's product because their RBAC (Role-Based Access Control) was too complex. When you show me a new feature, I evaluate it strictly based on the time-to-value for my junior developers."
By using synthetic data for product validation, you are simulating interaction based on the probabilistic patterns of thousands of similar, historical users.
2. Step-by-Step: How to Create AI Personas
Building a synthetic user focus group requires a strict process known as "Context Grounding." You cannot simply open ChatGPT and command it to "act like an angry user." You must architect the persona using your proprietary data.
Phase 1: Ingest "Voice of Customer" Data safely
To create an accurate AI persona, the model must consume real friction points.
- Export Historical Data: Aggregate transcripts from your last 50 user interviews (via Fireflies or Otter.ai), support tickets from Zendesk, and sales objections from Gong.
- Clean & Anonymize (Critical): Before passing data to any model, ensure all Personally Identifiable Information (PII) is completely stripped. Failing to do this violates data sovereignty laws.
- Vectorize: For enterprise setups, store this qualitative data in a secure vector database. This allows the AI agent to accurately retrieve specific, historical pain points during your simulation rather than hallucinating generic complaints.
Phase 2: Define the System Prompt Architecture
Your system prompt acts as the "operating system" for the synthetic user. It dictates their boundaries, biases, and goals.
Need more frameworks? Leverage these copy-paste prompts for product managersto quickly standardize your persona generation.
Phase 3: Run the Multi-Turn Simulation
Once the persona is grounded, execute synthetic customer interviews. Do not limit this to a single question; you must challenge the model.
- Simulating First Impressions: Present your landing page copy or pricing tier. Ask the agent, "What is the very first thing that confuses you on this page, and why does it make you hesitate to click 'Sign Up'?"
- Journey Narration: Ask the agent to "roleplay" navigating the checkout flow, outputting their internal monologue at every friction point.
- Pushback Testing: It is highly recommended to implement a multi-turn agent testing methodology. Argue with the AI. Tell the persona their objection is invalid and observe if they cave easily (a sign of a weak prompt) or hold firm to their designated constraints.
3. Use Cases: Rapid Prototyping with AI Users
Why are top PMs moving toward automated user testing AI? The primary driver is iteration speed.
- Validating Hypothesis with AI: Before interrupting a real customer's workday, run your core idea past the synthetic panel. If the AI agent—trained accurately on your historical data—finds the value proposition weak, your actual users almost certainly will, too.
- A/B Message Testing: Pit 50 different subject lines or feature naming conventions against your synthetic personas to rapidly predict the winner based on their defined psychographics.
- Pricing Sensitivity Checks: While an AI cannot flawlessly predict actual human willingness to pay, it excels at simulating comparative reactions (e.g., "As an enterprise buyer, this per-seat model feels highly restrictive compared to the flat-rate API usage I currently pay for").
4. The Ethics: Simulation vs. Reality in 2026
As we increasingly rely on advanced user research tools, we must strictly adhere to ethical synthetic data practices.
- Augment, Never Replace: Synthetic users exist to de-risk concepts and pre-validate flows. They do not replace the absolute necessity of human empathy and final user verification.
- The Echo Chamber Risk: If you train your AI agents exclusively on the feedback of your current, happy customers, the model will never accurately tell you why non-customers refuse to convert. You must deliberately engineer "Anti-Personas" and "Churned Personas" to avoid confirmation bias.
- Regulatory Transparency: Never present synthetic data to stakeholders or investors as "real user feedback." You must adhere to the EU AI Act product complianceguidelines, ensuring that any AI-generated insight is clearly labeled internally as "Simulated Confidence Scoring" rather than human telemetry.
Frequently Asked Questions (FAQ)
Can AI really replace human user interviews?
No. Synthetic customer interviews act as a rapid preliminary filter, not a replacement for human empathy. They help product teams discard flawed concepts before spending capital on real user recruitment. Final validation and the discovery of "unknown unknowns" still require actual human insight.
Which tools are best for synthetic user research in 2026?
Enterprise teams are heavily utilizing platforms like Kraftful and SyntheticUsers.com. For custom deployments, custom GPTs or agents built on Google's Gemini 3.1 Pro or Anthropic's Claude 4.7 are preferred due to their massive context windows, which allow them to process extensive CRM and support ticket histories without losing state.
Is setting up an AI focus group expensive?
Compared to traditional research, it drastically reduces user research costs. Instead of paying participant incentives ($100 to $300 per hour) and managing weeks of scheduling, you can run 1,000 synthetic simulations for the compute cost of a few API tokens. The primary cost is the initial engineering time required to build the secure data pipeline.
How do I trust the synthetic data isn't a hallucination?
Trust is established through context grounding. You do not ask an open-ended LLM for its opinion. Instead, you use a Retrieval-Augmented Generation (RAG) architecture. If the synthetic persona states, "This checkout flow is confusing," your system must require the agent to cite the specific historical support ticket or user interview transcript that informed that generated response.
Does generating synthetic data violate data privacy laws?
It can, if improperly managed. Feeding raw, un-anonymized customer data (PII) into public LLMs violates GDPR and the EU AI Act. Enterprise teams must scrub PII locally before vectorizing the data, or use zero-training-retention models (like secure enterprise instances of Azure OpenAI or AWS Bedrock) to maintain digital sovereignty.

Related Resources
- The AI Product Manager: The Complete Guide to GenAI, Agents & Automation – The central hub for AI PM skills.
- 50+ Copy-Paste Prompts for Product Managers – Includes specific prompts for creating user personas.
- ChatGPT vs. Claude vs. Gemini: Which is Best for PRD Writing? – Choose the right model to power your synthetic users.
- The "Agentic" PM: How to Manage Non-Human Team Members – Learn to manage your new AI workforce.
